



Pascari Branding and Accelerating AI
At FMS 2024, Phison devoted very important product sales home dwelling to their enterprise / datacenter SSD and PCIe retimer decisions, along with their shopper merchandise. As a controller / silicon vendor, Phison had traditionally been working with drive companions to ship their decisions to the market. On the enterprise facet, their tie-up with Seagate for the X1 sequence (and the subsequent Nytro-branded enterprise SSDs) is form of well-known. Seagate supplied the necessities itemizing and had a say contained in the remaining firmware prior to qualifying the drives themselves for his or her datacenter buyers. Such qualification entails a big useful helpful useful resource funding that’s potential solely by large firms (ruling out plenty of the tier-two shopper SSD distributors).
Phison had demonstrated the Gen 5 X2 platform finally 12 months’s FMS as a continuation of the X1. Nonetheless, with Seagate specializing in its HAMR ramp, and in addition to stopping completely totally different battles, Phison determined to go forward with the qualification course of for the X2 course of themselves. All through the larger scheme of factors, Phison furthermore realized that the white-labeling approach to enterprise SSDs was not going to work out in the long term. In consequence, the Pascari model was born (ostensibly to make Phison’s enterprise SSDs additional accessible to finish patrons).

Beneath the Pascari model, Phison has utterly completely totally different lineups concentrating on utterly completely totally different use-cases: from high-performance enterprise drives contained in the X sequence as successfully drives contained in the B sequence. The AI sequence is in the marketplace in variants supporting as so much as 100 DWPD (additional on that contained in the aiDAPTIVE+ subsection beneath).
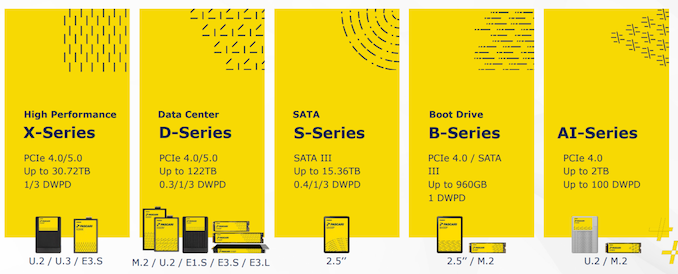
The D200V Gen 5 took pole place contained in the displayed drives, as a consequence of its most necessary 61.44 TB performance diploma (a 122.88 TB drive may also be being deliberate beneath the same line). The utilization of QLC on this capacity-focused line brings down the sustained sequential write speeds to 2.1 GBps, nonetheless these are meant for read-heavy workloads.

The X200, nonetheless, is a Gen 5 eTLC drive boasting as so much as 8.7 GBps sequential writes. It is on the market in read-centric (1 DWPD) and blended workload variants (3 DWPD) in capacities as so much as 30.72 TB. The X100 eTLC drive is an evolution of the X1 / Seagate Nytro 5050 platform, albeit with newer NAND and larger capacities.


These drives embrace all the same old enterprise decisions together with power-loss safety, and FIPS certifiability. Although Phison did not promote this considerably, newer NVMe decisions like versatile knowledge placement ought to change into a part of the firmware decisions ultimately.
100 GBps with Twin HighPoint Rocket 1608 Participating in taking part in playing cards and Phison E26 SSDs
Although not strictly an enterprise demo, Phison did have a station exhibiting 100 GBps+ sequential reads and writes utilizing a typical desktop workstation. The trick was putting in two HighPoint Rocket 1608A add-in collaborating in taking part in playing cards (every with eight M.2 slots) and putting the 16 M.2 drives in a RAID 0 configuration.

HighPoint Expertise and Phison have been working collectively to qualify E26-based drives for this use-case, and we could also be seeing additional on this in a later evaluation.
aiDAPTIV+ Expert Suite for AI Instructing
Actually one in all many additional fascinating demonstrations in Phison’s product sales home was the aiDAPTIV+ Expert suite. Finally 12 months’s FMS, Phison had demonstrated a 40 DWPD SSD to be used with Chia (fortunately, that fad has delicate). The corporate has been engaged on the extraordinary endurance side and moved it as so much as 60 DWPD (which is customary for the SLC-based cache drives from Micron and Solidigm).

At FMS 2024, the corporate took this SSD and added a middleware layer on extreme to make it doable for workloads hold additional sequential in nature. This drives up the endurance ranking to 100 DWPD. Now, this middleware layer is certainly a part of their AI educating suite concentrating on small enterprise and medium enterprises who mustn’t have the funds for a full-fledged DGX workstation, or for on-premises fine-tuning.
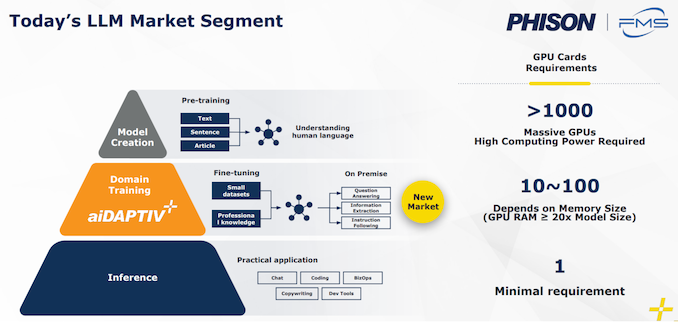
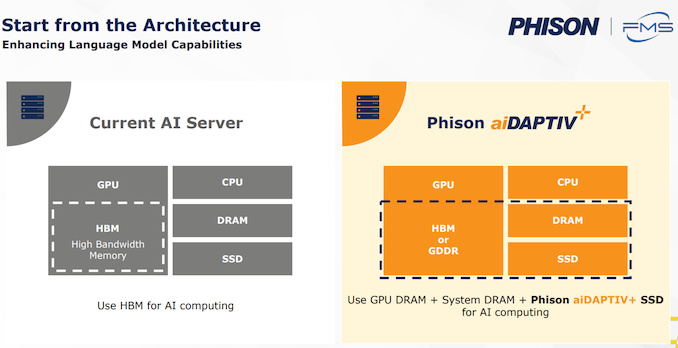
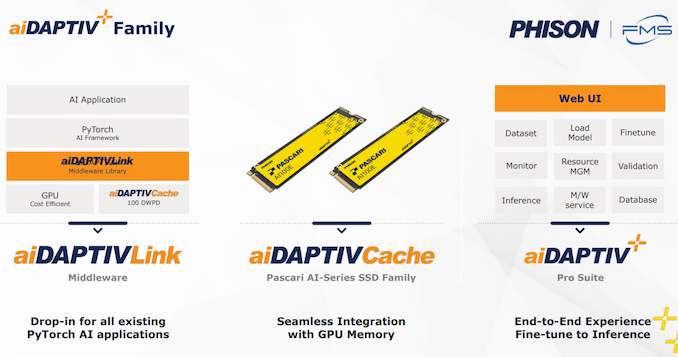
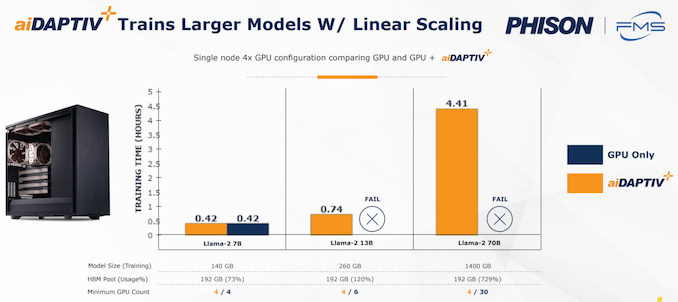
Re-training fashions by utilizing these AI SSDs as an extension of the GPU VRAM can ship very important TCO advantages for these firms, because of the pricey AI training-specific GPUs will seemingly be modified with a set of comparatively low-cost off-the-shelf RTX GPUs. This middleware comes with licensing choices which can be primarily tied to the acquisition of the AI-series SSDs (that embrace Gen 4 x4 interfaces in the intervening time in every U.2 or M.2 form-factors). The utilization of SSDs as a caching layer can allow fine-tuning of fashions with a really large variety of parameters utilizing a minimal variety of GPUs (not having to make the most of them primarily for his or her HBM performance).


